
1 查询过程
查询可以分为逻辑查询和物理查询。
逻辑查询
sql不像其他语言,sql执行不一定是按照顺序执行的。
对于一条查询语句而言,每一个关键字都有自己的逻辑执行顺序。
如下面的sql语句:
<7> select
<8> distinct ...
<1> from table
<3> <left/right> join table2
<2> on ...
<4> where ...
<5> group by ...
<6> having ...
<9> order by ...
<10> limit...
左边的数字代表着执行的顺序。
这个顺序看着有些奇怪,可能需要解释一下。
| 关键字 | 说明 | 产生的表 |
| ——– | —————————————- | —— |
| from | 左边table和右表table2连接,产生笛卡尔积 | 虚拟表VT1 |
| on | 符合on后面条件的行保留下来,插入到新的虚拟表 | VT2 |
| join | 如果是外连接(Outer join),即left loin ,right join,则将on未匹配的行作为外部行,添加到虚拟表VT2中 | |
| where | 对VT3应用where过滤条件,符合行才会被插到虚拟表VT4中 | VT4 |
| group by | 对VT4的数据进行分组,产生VT5 | VT5 |
| having | 对VT5应用having过滤,形成VT6 | VT6 |
| select | 选择指定的列,插入到VT7 | VT7 |
| distinct | 去除重复数据,产生VT8 | VT8 |
| order by | vt8的数据按照指定列排列,产生虚拟表VT9 | VT9 |
| LIMIT | 取出指定的行数据,返回给用户 | VT10 |
| | | |
从中我们可以发现什么呢?
- 对于两个表的查询,一个会首先产生一个笛卡尔积。如果两张表的数量都特别大,那将会产生庞大的笛卡尔积,影响查询速度;
- 所谓外连接(left/right join),就是在on匹配了以后,还要插入未匹配的外部行;
- 笛卡尔积、各种过滤以后,才会取出指定的列;
- distinct居然排这这么后面!
- 因为最后的结果出来了才能进行排序,所以order by 的执行顺序很靠后(并不是一边取出数据,一边排序的);
- 即使采用了limit,查询以后会先把数据都查出来,只不过返回给用户的数据量少一些而已(实际上分页减少的是数据的传输时间,而不是查询时间)。
- 为什么where后面不能用min、max、count这些分组函数?因为where执行的时候,还没有执行group by分组呢!而且也没有order by,根本无法判断大小、无法做任何的统计!
了解到这些执行顺序,对于后面的索引学习很有帮助。到时候我们将会知道,在有多个索引的情况下,mysql将会选择哪一个?
物理查询
逻辑查询描述了应该产生什么样的结果,我们无法太依赖于逻辑查询。我们需要通过一些物理手段来进行优化。物理查询是没有绝对的,条件不同,所采用的优化方式可能也会不同。但是一定会保证物理查询和逻辑查询的处理结果是一致的。
比如,物理查询会根据索引来优化,同样也会根据表的数据量大小来进行优化。
边边角角的小知识
- select的时候,count(1)/count(*)都包括了对null行的统计,而count(字段)不包括对该字段为null的行的统计。
- limit 应该和order by 一起使用。没有order by的查询数据,顺序可能是无序的,单独使用limit的数据可能是错页的。并且,要选择对所有的行都能order by 的字段。
- limit m,n ,在数据量很大的时候。当选择最后几页的时候,效率比较低,表现的结果就是查询很慢。假如有100万条结果,如果从99万条开始,取5条,扫描到第99万条数据同样很耗时。
2 索引
先从简单的角度来解释什么是索引。
索引就是将一条记录的一个或多个字段复制出来一份,然后根据一定规律对其进行排序,形成一种数据结构,便于快速查询。索引用于快速定位记录的位置,减少查询时间。但是需要占用更多的空间资源。
缓冲池
Mysql是基于磁盘的关系型数据库,对于磁盘的读取是远远慢于内存的,所以,需要用一块内存区域来做为缓存池。
缓存池的作用是将磁盘中读取的“页”放入缓冲池。
读取数据时,先去缓冲池查找数据是否在已被缓存的页上,如果不在则继续去读取磁盘的页。
写入数据的时候,先在缓冲池对页进行修改,然后异步写回磁盘上。
所以,缓冲池的大小决定了数据库的性能。
顺序读取与随机读取
顺序读取的速度要远远快于随机读取的速度。
顺序读取:指的是顺序读取磁盘上的页,指的是逻辑顺序;
随机读取:访问的页是不连续的;
页上有区,区的存在可以保证至少一个区内的所有页的读取是顺序的。但区与区之间的顺序不能保证。
二分法
当一组数据是有规律排列(有序)时,二分法的 平均 查找次数的最少的。所以,假如数据库存储的数据是有序的,我们就可以采用二分法的思想来进行查询。
二叉查找树和平衡二叉树
平衡二叉树
符合二叉查找树的定义;
任何节点的两颗子树的高度最大差为1;
查询性能接近最高(最优二叉树)。但是维护一颗平衡二叉树的时候,需要耗费一定代价。
思考:
如果是在磁盘上维护平衡二叉树,开销影响很大;若是在内存中维护平衡二叉树,则开销显然是可以接受的。
B+树
先来看一下B+树的形状是怎样的
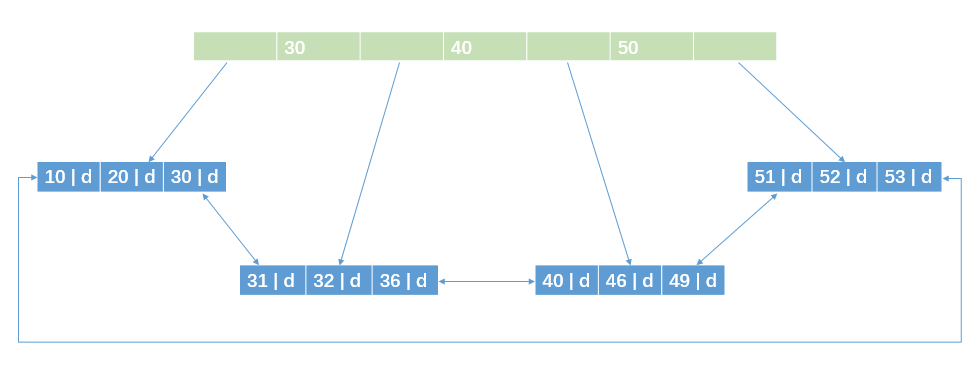
只看一下最典型的特征:
- 可以分为根节点和叶子节点:根节点只是用作索引,叶子节点的数据除了有数据,还记录了对应的值所处的真实位置(精确到页上)。所以,所有的元素最终都会出现在叶子节点上。(当然,一颗B+树可能存在多个根节点,并不是想上图中只有一个根节点)
- 根节点中任一元素左边的指针,总是指向小于或等于该元素的值的节点;右边则是大于或等于该元素的节点。
- 叶子节点之间有指针链接,形成一个有序链表。可以利用这个特点来做范围查询:先通过根节点定位到范围最小元素,然后采用链表特性遍历到最大值,也可以不用回到根节点上去比较了。
B+树的操作
基本操作有:插入、旋转、删除。
每一次操作后,B+树可能都需要保持自己的平衡,所以在不同情况下会有不同算法去做相应处理。
B+树索引
聚集索引
数据的存放是按照一定规律存放的。
具体按照哪种规律存?这就看聚集索引是如何指定的了,主键就是最广泛的聚集索引。聚集索引只能有一个。因为存的规律只有以一种规律存呀。
存储内容:(主键,真实位置)。
辅助索引
辅助索引则主要为了查询(当然聚集索引也是,但是辅助索引不会影响到真实数据的存放位置),将查询定位到聚集索引上去。查询的时候,先找到对应的主键值,如此便可以定位到聚集索引,最后通过聚集索引找到记录的真实位置。对于:
create index index_name on table(name)
意思是将name字段的值都复制一份,然后跟其对应的主键一起存储。
存储格式:(name的值,主键值)。
覆盖索引
覆盖索引不是一种索引,而是描述了一种场景。在多字段索引的情况下,如
create index index_name_and_age on table(name,age)
如果要查询某用户的年龄,如
select age from table where name= **
那么小根据辅助索引找到对应的name,但是因为是多个字段的联合索引,此时辅助索引已经存了age,那么就不需要通过主键定位到聚集索引去查询了,也就是辅助索引的覆盖了聚集索引。
InnoDB B+树索引
InnoDB 的数据存放本身就是具备一定规律的,同样是按照B+树来组织(组织索引表)。
有聚集索引和辅助索引两种类型的索引。
索引页的大小都是16kb,且不能修改。
MyISAM B+树索引
所有行数据都存在MYD文件中,存放于MYI文件中。
其索引类型都是辅助索引。
主键索引和其他索引不同之处在于:主键索引是唯一的,是非空的。
索引页大小为1KB。
联合索引
对表上的多个列进行索引,称之为联合索引。
好处是可以对第二个键值进行排序,如此便不用一次额外的排序开销了:
假设有索引 (a,b)
当第一个键值,即a位确定的时候,b位的数据是有序的。例子:当a=7 order by b,或者a=7 and b>6,此时能使用(a,b)索引。
但是a>7 and b>6不会用到(a,b),因为a不确定的时候b位是无序的。
边边角角的小知识
索引只能够定位到页,页上用二分法来进行查询。
B+树索引具有高扇出性:
一个模块调用其他模块的个数,称为该模块的扇出。扇出越大,设计该模块时需要考虑的问题就越多,因而复杂性越高。
一个模块被其他模块调用的个数,称为该模块的扇入。扇入大些,一般不会影响问题的复杂性,而且扇入越大,说明该模块的复用性越好。