
概述
什么是缓存
源头:磁盘IO,超慢!
内存分配、寻址、持久化,都影响到了响应时间,进而响应吞吐量
系统性能要求,用户体验要求
吞吐量、响应时间等。
CPU怎么做
划分出一块高速缓存,用于存储即将、可能用到的数据,用于数据的高速交换。
重点
缓存是数据的冗余
空间换时间
追求速度和吞吐量
缓存的分类
| 类型 | 说明 | 举个栗子 |
| —– | ———————— | —————————————- |
| 客户端缓存 | B/S架构下,数据缓存于客户端 | 浏览器缓存:HTTP支持,lastModyfied/T-Tag、Cache-Control/Expires
页面缓存:H5支持,LocalStorage/SessionStorage
App缓存:文件、SQLite、内存 |
| 网络缓存 | 客户端与服务端之间。用于代理或者响应客户端的请求 | Web代理(正向):Squid
边缘代理(反向):Nginx、CDN |
| 服务端缓存 | 真正提供数据的”源头“ | 数据库缓存
应用级缓存
|
| | | |
缓存结构

由上图可以看到,Redis属于服务端缓存。
值得注意的是,通常我们是在应用服务器层和Redis交互,而上图中在接入层便同Redis进行交互:如果Redis有对应的缓存,请求便不会转发到服务器层。这能增加应用的吞吐率。
Redis的特性
Redis可以做什么
记录帖子点赞数、点击数
记录点赞列表、评论列表
热点数据
计数器
排名、热榜
用户行为,如PV/UV
延时队列
限流
…
我们现在用Redis做什么
- 分布式锁(下单、登陆等)
- 数据缓存
单线程
作为一个单线程程序,Redis不必耗费心机去处理多线程所带来的种种问题
1. 线程切换;
2. 线程间通信;
3. 资源共享;
......
Just keep it Simple!
为什么单线程也能够作为高性能的典范呢?
这是因为Redis采用了非阻塞IO。
非阻塞IO
正常情况下,我们最熟悉的IO操作其实是阻塞IO。

接收数据的伪码:
while(true){
String data = accept();
handle(data);
}
为了进行高速的读写操作,客户端和服务端都存在一个 发送缓冲、接收缓冲,分别用于发送数据和接收数据。
在阻塞IO中,当客户端和服务端建立了连接后,客户端要想实时拿到服务端发送过来的数据,线程就必须一直阻塞,直到有数据过来才去处理。这种场景下,如果又要接收到数据,又要处理客户端自己的任务。那就只能用多线程来处理。
而Redis采用的非阻塞IO是,recv buffer中有多少数据,就读多少数据,读完了马上就去处理别的事情。
发送数据的时候亦是如此,send buffer中有多少数据就发发送多少数据,发完了就处理别的事情去了,等到需要发数据的时候再继续发送。当send buffer不够大的时候,Redis同样不会阻塞,它会等到send buffer空间足够的时候再回来继续发送数据。
多线程程序是通过 切换线程、线程间通信 来解决阻塞问题的。
单线程是通过 切换任务 来解决阻塞问题的。
多路复用
非阻塞IO中存在一个问题,单线程程序是怎么知道什么时候应该去接收数据,什么时候应该去发送数据呢?显然,我们可以通过轮询来解决这个问题。但是肯定不能由用户线程去做这项工作。
所以必须存在一种机制:主动通知 用户线程去处理相关的事情。这种机制就是多路复用(事件轮询)。
多路复用机制 由 操作系统提供,如Linux的Epoll、Select、Poll。
过期策略
既然Redis是单线程,那么如何处理key值过期的问题呢?如果某个时间点,大量key同时过期,是不是Redis光处理这些过期key就要耗费很长的时间,从而导致Redis处于阻塞状态?
为了防止阻塞,Redis采取了一些策略。
懒汉式删除
过期了不删除,等到要用到这个key的时候,先判断key是否过期,若过期了直接返回不存在。若是客户端长期不查询过期的key,会造成大量无用的过期key占用内存的情况。
定期扫描
定期去扫面有哪些key过期了,统一删除。为了保证对外服务的能力,扫描时间不会太长:超过固定的时间则不继续扫描。
持久化
作为缓存,Redis害怕突然的宕机,一旦宕机,所有缓存数据必须重建,相当于触发了一次缓存雪崩,所以需要持久化。
作为数据库,Redis更需要持久化。
而众所周知,Redis的数据都是在内存里。想要持久化,少不了磁盘的IO操作。
而IO操作势必会影响到Redis的性能。那么Redis是如何权衡利弊的呢?
Redis支持两种持久化方式
快照
AOF(Append Only File)
快照
将某一时刻的内存数据状态保存至磁盘上
| 快照文件后缀 | .rdb |
| —— | ———————— |
| 可执行指令 | BGSAVE 异步写
SAVE 同步写 |
快照的生成过程
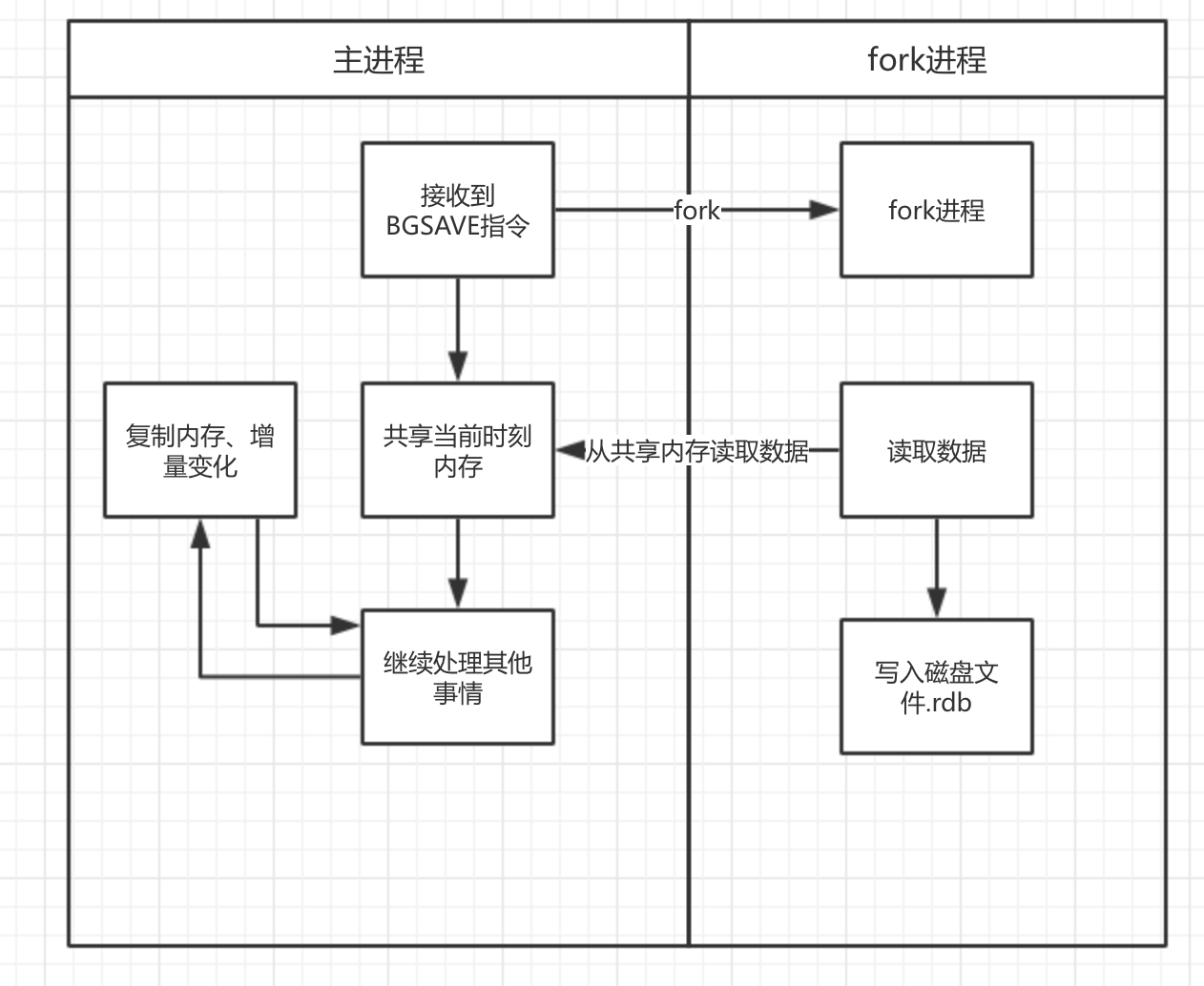
既然Redis是单线程的,生成快照需要磁盘IO,必然是同步操作。这样不会阻塞Redis的正常读写吗?
实际上快照的生成采用了COW(Copy On Write)机制:
- 即从当前的Redis进程中fork出一个子进程,子进程和父进程共享当前内存中的代码段和数据段。
- 父进行继续接受客户端指令,遇到写入、修改执行时,不直接修改共享内存的数据,而是将要修改的key所在的那一段的数据复制一份出来,在备份中进行修改。如果生成快照的时间太长,那么需要复制的数据段会越来越多。但最多也不会超过原数据的两倍。而且作为缓存,大部分应该都是“冷数据”无须修改的。
- 子进程用共享的数据段来生成快照,不断遍历,写入。
优点
- 存的是数据的某一时刻的状态(不用管数据经过何种逻辑最终导致这种状态),文件体积小;
- 恢复数据速度较快。
缺点
- 快照是某个时刻的全量数据,生成快照较耗时。
- 创建子进程需要耗费资源,且该函数是同步的,需要要等待系统返回是否成功。
- 写快照期间,Redis主进程修改数据的时候要复制数据,耗内存。
- 因为耗时,所以很久才备份一次,数据不全,易丢数据。
创建快照的方式
- 执行BGSAVE指令:fork一个子线程,异步,不阻塞。但耗内存(double)。
- SAVE执行:阻塞其他指令。不耗内存。
- 配置文件配置了save 60 10000,满足条件自动触发BGSAVE。
- 收到SHUTDOWN关闭命令,会执行一个SAVE指令,SAVE结束后关闭server。
- 从节点发送了一个SYNC指令,而主节点并非正在执行BGSAVE或者刚执行完BGSAVE。
AOF
增量持久化,相当于把所有修改指令都存起来。恢复数据的时候只需“重放”AOF文件即可。
| 文件后缀 | .aof |
| —- | —————— |
| 策略 | always、everysec、no |
写aof流程
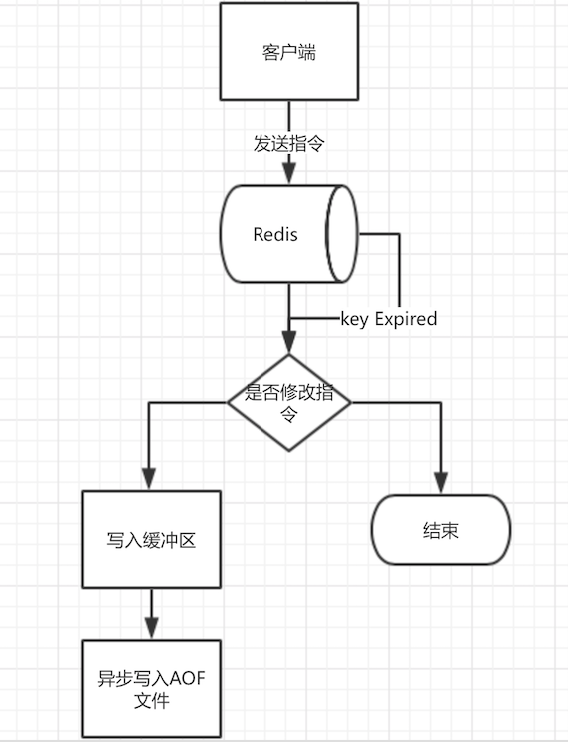
一般推荐everysec写入,awlays将会降低Redis的写入性能,并且会降低磁盘的寿命。
当然,everysec缺点也很明显:如果某一秒的数据没有写入成功的话,那一秒的数据便会丢失。如此配置Redis可能导致1s数据的不精确(但那也比快照好很多了),一般场景下是可以接受的。
优点
- 数据丢失较少,一般只丢一秒钟的数据;
- 单次持久化的数据量较小,持久化速度比较快;
缺点
- aof中包含了数据最终状态的所有逻辑,aof文件比较大;
- 恢复数据的时候比较慢,Redis启动时间比较长;
AOF文件重写
当aof文件太大的时候,可以对aof文件瘦身。若要保持redis的单线程特征,只能像快照一样,创建一个子进程去执行了。所以,快照的内存问题和创建子进程耗资源的问题,重写AOF文件都会碰到。
可以在客户端手动执行bgrewriteaof指令告诉redis-server进行一次重写。也可以通过配置文件配置的方式来进行:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
上面表示,当aof文件提交大于64MB,且提交比上次重写体积大了100%后,自动触发重写操作。
写AOF的步骤
- 先执行指令,再写入内核分配的缓冲区中。
- 调用操作系统的fsync函数异步刷到磁盘,多久刷一次,根据配置appendfsync指定。
redis指令先执行,然后才会写日志文件里。既然redis要维持高性能,就没有必要像关系型数据库保持ACID。Redis优先考虑执行是否能否执行。
优先执行指令,然后再去尽可能保障其持久性。
混合持久化
既然创建快照太慢,AOF文件又太大,那么可以考虑二者混合使用。
Redis 4.0 支持了这种混合持久化。
配置:
# When rewriting the AOF file, Redis is able to use an RDB preamble in the
# AOF file for faster rewrites and recoveries. When this option is turned
# on the rewritten AOF file is composed of two different stanzas:
#
# [RDB file][AOF tail]
#
# When loading Redis recognizes that the AOF file starts with the "REDIS"
# string and loads the prefixed RDB file, and continues loading the AOF
# tail.
#
# This is currently turned off by default in order to avoid the surprise
# of a format change, but will at some point be used as the default.
aof-use-rdb-preamble no
重写aof文件时,可以将aof的结构改变成
[RDB file][AOF tail]
包含了两个部分。恢复数据时,先从rdb恢复,再从AOF的增量中恢复。
常用配置
dir ./ #根目录
dbfilename dump.rdb # rdb文件名
rdbcompression yes #是否压缩rdb文件
save 900 1 # 什么条件触发一次BGSAVE
appendonly no # 是否写aof文件
appendfsync everysec #写aof的策略:everysec/always/no
...
管道
即pipeline。
客户端发送指令给Redis的时候,需要一次请求,一次应答。若一个客户端事务中,需要执行N个指令,通讯次数就是 N*2。
Redis执行速度很快,而我们将大部分的时间都浪费在了网络上。为了减少通讯带来的开销,可以通过管道来操作。
大致思路是:打包将所有要操作的指令一次性发送给Redis,Redis执行完成后一次性返回结果。
注意
如果开启了管道,那么是不能够立即拿到Redis的返回结果的。
你就不能进行如下的操作了
int value = redis.getKey("king");
if value == 1
redis.set("test", "ok");
else
redis.set("test", "not ok");
上述伪代码所示,需要根据king的值来作为判断依据来决定test的值。由于开启了管道,redis命令是一次性发送的,是没有办法立即拿到king对应的value的。所以代码会报错。
原子性
对于Redis来说,在一定程度上,我们需要保持操作原子性。比如,分布式锁。
首先我们要明确,因为Redis的单线程特性,在同一个Redis实例上进行操作,单个指令肯定是原子性的。但是如果是同时操作多个指令,就很难保证其原子性了。
就比如
redis.incr(‘article:121’);
redis.incr(‘hot:list:121’);
假设用户某个操作将会执行两个指令,通常情况下需要发两次请求,第一个指令执行成功后,可能第二个指令没成功,那么对于这整个操作而言,就不具备原子性了。
watch + 事务 + pipeline
先watch变量,再开启事务,当变量有变化,立即discard。在某种程度上可以达到原子性。
watch ‘article:121’
while(true){
redis.incr(‘article:121’);
redis.incr(‘hot:list:121’);
}
lua
通过lua脚本可以达到原子性的要求。并且执行的lua可以持久化在服务器上,以后每次要调用的时候只需要传对应的sha值即可执行同样的lua脚本。
setnx
setnx(key, value)表示:如果key不存在,才会set成功,否则set失败。分布式锁通常都用这个指令。
但是细心的你可能会发现:
setnx不支持在设置key的时候设置过期时间!
如果我们 setnx 成功了,为了预防死锁,往往需要继续继续设置过期时间 expire (key, timeout)。
解决方案:
用LUA脚本进行原子性操作
setnxAndExpire.lua
local key = key[0] local value = key[1] local timeout = key[2] local success = redis.call('setnx', key, value); if success return redis.call('expire', timeout); else return -1使用set命令
从2.6.12后,Redis给set命令增加了几个参数
SET KEY VALUE [EX seconds] [PX milliseconds] [NX|XX]EX seconds− 设置指定的到期时间(以秒为单位)。PX milliseconds- 设置指定的到期时间(以毫秒为单位)。NX- 仅在键不存在时设置键。XX- 只有在键已存在时才设置。在
jedis中我们可以这样使用jedisCmds.set(key, lockValue, "NX", "PX", lockMs)所以,现在set指令已经完全可以替代setnx、setex了。
事务
指令
multi 开启事务
exec 执行事务
discard 丢弃事务
注意
Redis的事务只能保证隔离性,无法保证原子性(一串指令中,一个执行失败了,已经执行成功的指令并不会回滚)。
所以一般 先 (watch 变量 + 事务) 。
集群
当一台Redis挂掉的时候,如果没有备用的Redis来接替,程序可能就会报错。后端服务器也会承受大规模请求的涌入。
那么,Redis的集群怎么做?而要说Redis集群,得先从Redis的主从同步说起。
Redis的主从
只有master可以进行写操作,从节点只进行读操作。
如果在从节点执行修改操作则会报错:
127.0.0.1:6380> set test:6 666
(error) READONLY You can't write against a read only slave.
最简单的Redis主从
从节点配置
slaveof ip port #将指定的ip/port作为master
主节点配置
bind 0.0.0.0 # 允许所有ip连接redis,最好改为指定的ip比较安全
当slave节点启动后
4653:S 05 Oct 14:43:34.248 * MASTER <-> SLAVE sync started
4653:S 05 Oct 14:43:34.274 * Non blocking connect for SYNC fired the event.
4653:S 05 Oct 14:43:34.319 * Master replied to PING, replication can continue...
4653:S 05 Oct 14:43:34.378 * Partial resynchronization not possible (no cached master)
4653:S 05 Oct 14:43:34.405 * Full resync from master: 0feed6323dcded0abf414bfe3662c3506ae3f817:0
4653:S 05 Oct 14:43:34.469 * MASTER <-> SLAVE sync: receiving 212 bytes from master
4653:S 05 Oct 14:43:34.470 * MASTER <-> SLAVE sync: Flushing old data
4653:S 05 Oct 14:43:34.471 * MASTER <-> SLAVE sync: Loading DB in memory
4653:S 05 Oct 14:43:34.471 * MASTER <-> SLAVE sync: Finished with success
4653:S 05 Oct 14:43:34.472 * Background append only file rewriting started by pid 4654
4653:S 05 Oct 14:43:34.497 * AOF rewrite child asks to stop sending diffs.
4654:C 05 Oct 14:43:34.498 * Parent agreed to stop sending diffs. Finalizing AOF...
4654:C 05 Oct 14:43:34.498 * Concatenating 0.00 MB of AOF diff received from parent.
4654:C 05 Oct 14:43:34.498 * SYNC append only file rewrite performed
4653:S 05 Oct 14:43:34.552 * Background AOF rewrite terminated with success
若出现类似日志即表明已经从master同步数据成功。
主从复制过程
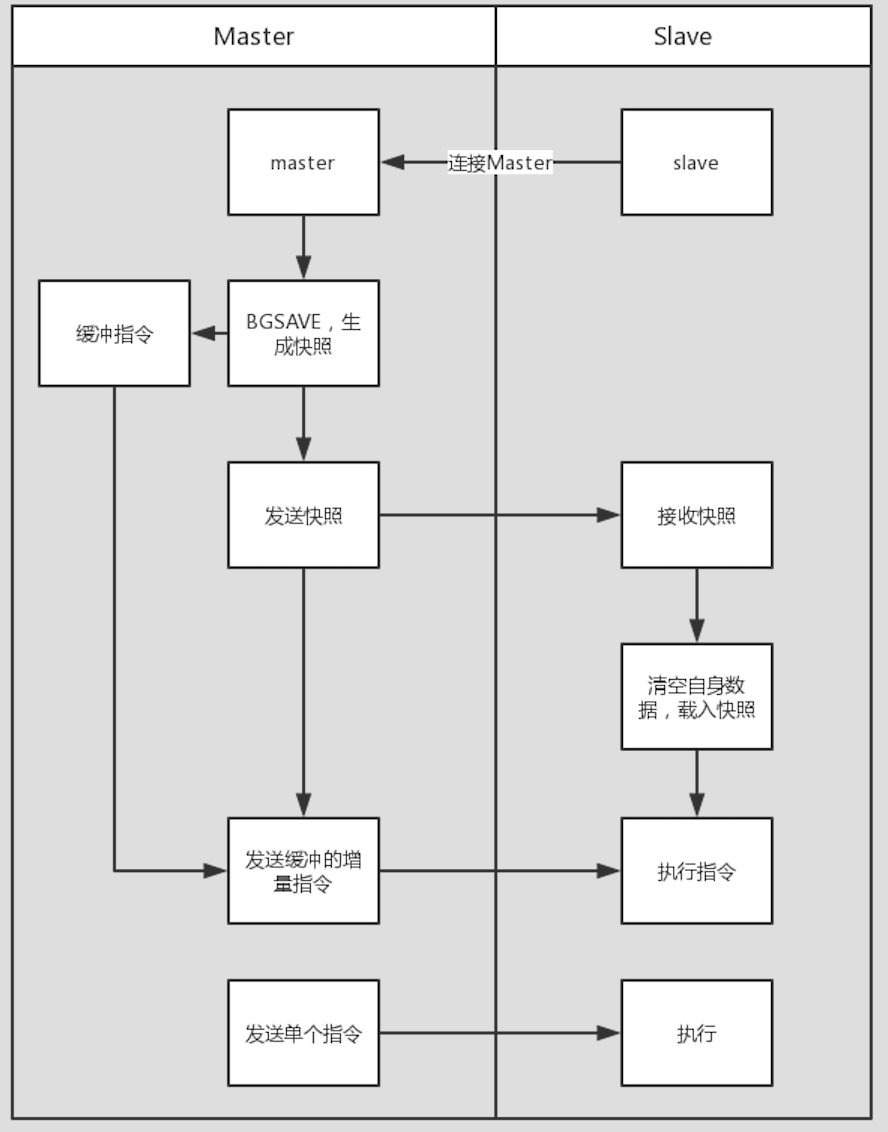
- 连接master服务器,发送SYNC指令;
- master执行BGSAVE,生成当前时刻快照;同时开始记录同步完成前的所有写入指令到缓冲区;快照生成后向slave发送快照;
- slave清空自有数据,载入快照;
- master向slave发送缓存区中的写入指令,slave挨个执行;
- 此后,一旦master写入z指令->发送给slave->slave执行同样指令;
不支持主主复制,只支持主从复制。
注意
不要太多台redis slaveof同一台redis做master,否则会导致这台master频繁进行BGSAVE,影响,master的性能。尽量形成层层的树状的主从树。
主从同步的方式
根据主从复制的流程,可以将同步方式划分为
- 增量同步(master发送单个指令、slave执行);
- 快照同步(slave启动的时候,或者master缓冲区覆盖的时候);
从节点启动时,先进行的是快照同步,此后主从之间的同步方式为增量同步。我们知道,主节点的写入指令是存在缓冲区中,缓冲区大小是有限的。
如果写入太快,尚来不及将缓冲区数据同步到从节点,那么缓冲区的数据将会被覆盖(实际上缓冲区是一个圆形结构)。为了让从节点不丢失被覆盖的这部分更新,所以一旦出现缓冲区覆盖的情况,redis立即会进行一次快照同步(也就是来一次BGSAVE)。如果快照同步期间,缓冲区又出现覆盖的情况,又会发起一次快照同步,很可能导致死循环。所以,需要配置恰当的缓冲区大小。
client-output-buffer-limit slave 256mb 64mb 60
表示,如果给从节点的缓冲区,假设当前缓冲区大小为X,
- 若 X > 6M,则进行一次快照同步;
- 若 6M < X < 256M ,时间持续60秒,则进行一次快照同步;
无盘复制
快照同步在master中,有几处耗时操作:
- 创建子进程;
- 子进行将内存数据写入磁盘,形成快照文件;
- 将快照发送给从节点;
如果只是要发送给从节点的话,其实可以忽略文件写入,直接将内存数据通过socket传输给从节点,从节点收到完整的快照数据成功后,再开始载入。如此便节约了磁盘IO的开销。
Sentinel
主从复制已经解决了redis备份的问题,但是一旦Master出现了故障,总不可能是手动将Slave设置为Master吧?
通过Sentinel(哨兵模式),可以自动进行这个操作。
Sentinel是Redis提供的一种集群方案,安装Redis的时候,会看到sentinel的配置文件,说明Redis默认已经集成了Sentinel。
要点
- sentinel中间件监控Redis服务
- 数据不分片
- 解决故障转移问题,自动选举新Master
版本
redis 2.6 Sentinel1.0 (已废弃);
redis 2.8 Sentinel2.0(稳定);
启动方式
redis-sentinel /path/to/sentinel.conf
redis-server /path/to/sentinel.conf --sentinel
流程图
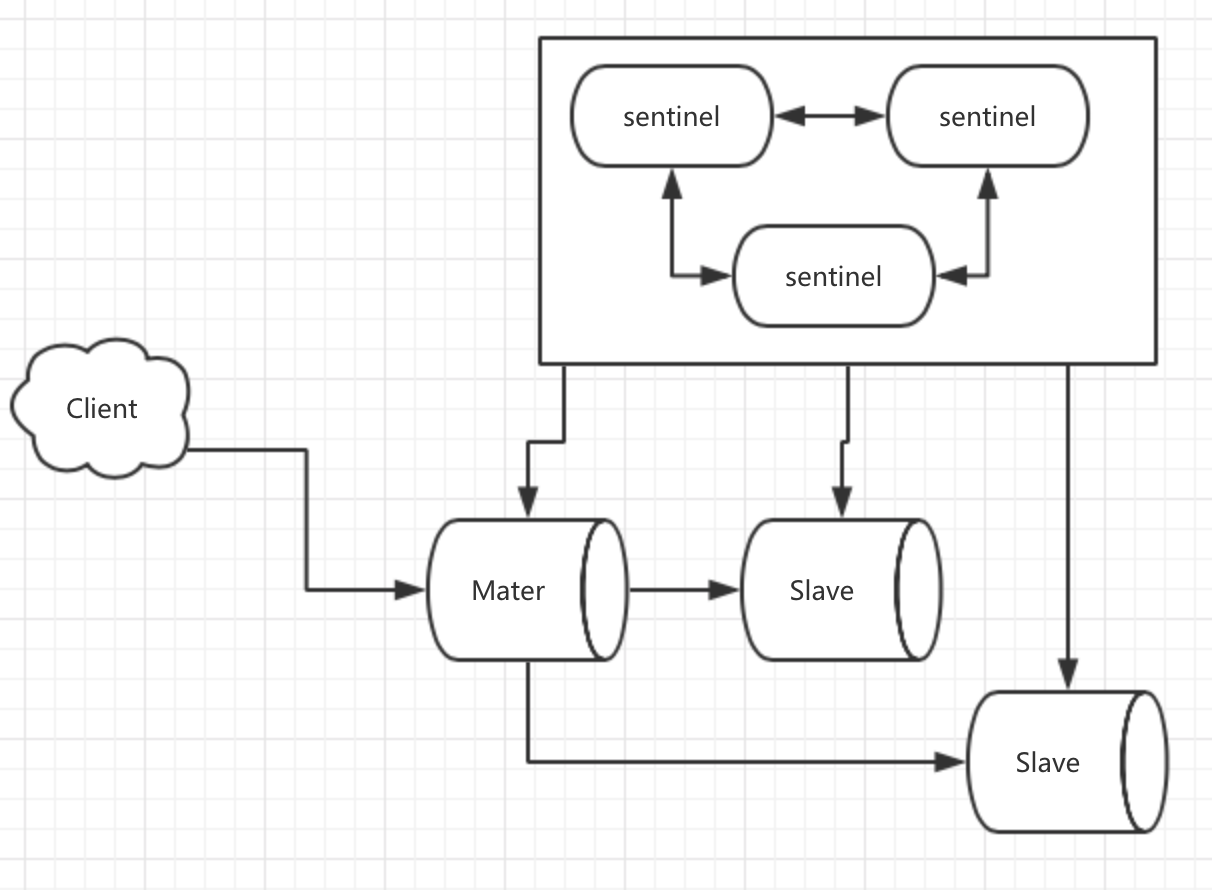
当master出现问题之后,自动将一个slave变为master。
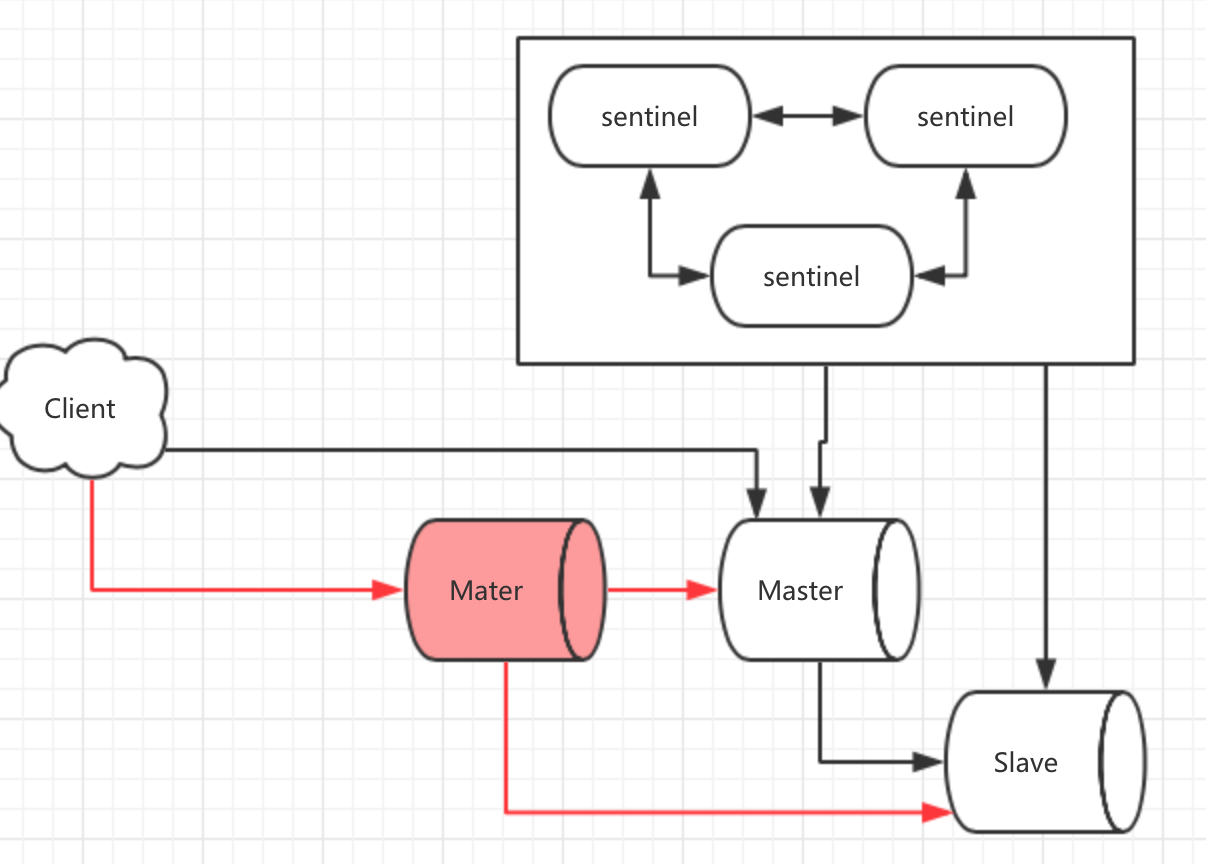
从上图来看,sentnel模式不仅仅只是服务端的配置。客户端也必须做出一定的变化:比如,当master变化时,Client需要得知新的Master的地址。此后发送的修改指令都往Master上发。
设置新master的步骤
- 向新的master发送
slaveof no one - 向其他slave节点发送
slaveof masterip port
Codis
(未收录)
Redis Cluster
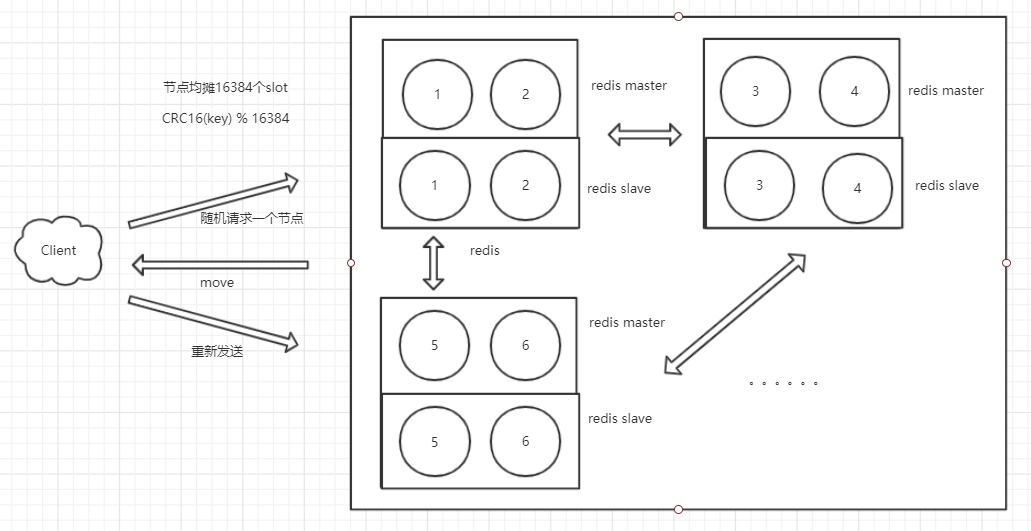
Redis Cluster是官方提出的解决方案。
此集群方案是去中心化、去中间件,每个redis节点都是平等的。
sentinel 和 Codis 需要一个sentinel或者proxy来协助转发、监控,redis cluster方案中,redis自己就可以完成这样的转发、监控。
要点
- 划分出16384个slot,各个节点均摊slot。
- 数据是分片的:每个key都存在固定的redis节点上。
优点
- 高可用
- 无须中间件
缺点
协议异常复杂,运维存在一定困难
转发,相当于增加了一次通讯开销
多指令的请求,比如事务、管道
请求流程
- 客户端随机向redis集群中任一master实例发送set指令。
- redis 对key取模,如果key不是存在当前redis实例,就要回复一个MOVE,并携带正确的slot地址;客户端收到MOVE指令后,重新向正确的slot发送指令。
注意
使用Redis Cluster需要客户端的支持,客户端要支持Redis Cluster协议。比如
- 支持接受MOVE指令,进行指令的重发;
- 获取集群的信息,知道要往哪儿发;
缓存典型问题
缓存穿透
问题
场景:请求数据库中不存在的数据,缓存中必定没有该数据,所以也必定会溯源到应用服务器去查询。
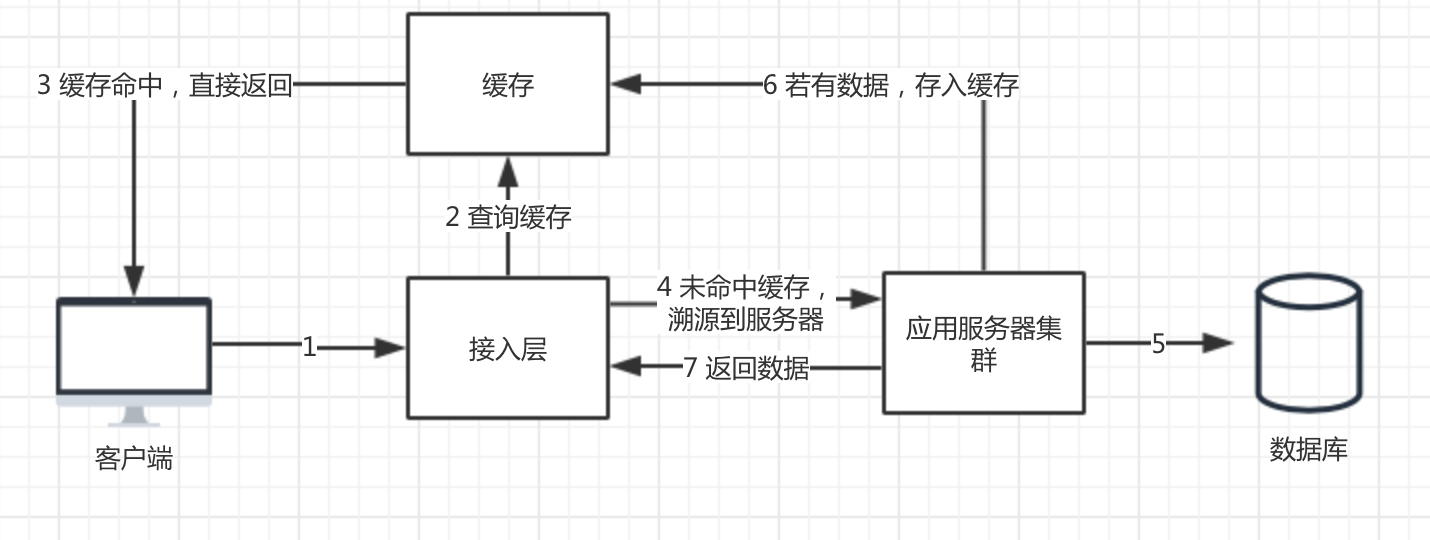
如图所示。
- 当有缓存的时候,只需要走123即可;
- 没有缓存的时候,必定要走145(6)78;
- 如果没有6,那么缓存一定不存在,导致每次都走14578,相当于缓存根本不存在,形成缓存穿透;
解决方案
- 参数过滤
加强参数校验,将存在参数不合理、不合法的请求过滤掉。比如某请求中,userid<0,应直接返回数据异常;
- 缓存Null
如果你在代码层采用AOP方式进行缓存操作。且用到了spring的spring-data-redis。
1.8之前,spring-data-redis 是不支持null 值的写入的,如果你使用的版本刚好>=1.8,那么恭喜你,1.8版本已经支持null值得写入在,在RedisCacheManager新增了一个Construct ,新增了一个参数cacheNullValues ,默认这个参数是false。
RedisCacheManager 相关源码如下所示:
/**
* Construct a static {@link RedisCacheManager}, managing caches for the specified cache names only. <br />
* <br />
* <strong>NOTE</strong> When enabling {@code cacheNullValues} please make sure the {@link RedisSerializer} used by
* {@link RedisOperations} is capable of serializing {@link NullValue}.
*
* @param redisOperations {@link RedisOperations} to work upon.
* @param cacheNames {@link Collection} of known cache names.
* @param cacheNullValues set to {@literal true} to allow caching {@literal null}.
* @since 1.8
*/
@SuppressWarnings("rawtypes")
public RedisCacheManager(RedisOperations redisOperations, Collection<String> cacheNames, boolean cacheNullValues) {
this.redisOperations = redisOperations;
this.cacheNullValues = cacheNullValues;
setCacheNames(cacheNames);
}
若你的版本大于等于1.8版本,我们只需要调用该construct,传入true即可。
如果你采用的是1.8以前的版本,那么可以考虑自己实现一套缓存null的逻辑。
即实现一个包装类BasePOWrapper:
public class BasePOWrapper {
private Object value;
public BasePOWrapper(Object value){
this.value = value==null ? Constants.NULL_VALUE : value;
}
public Object getValue() {
return value;
}
public boolean isNullValue(){
return this.value.equals(Constants.NULL_VALUE);
}
}
大致思路就是,在存储cache值的时候,都包装成BasePOWrapper,然后再存到redis。
这里存在的一个问题是:
没有必要将所有不存在的数据都缓存起来。
打个比方:若有人写个脚本,循环查询1亿个不存在的数据,那么缓存将要存1亿个Null吗?这显然不合理。
对于此种情况应及时发现和拦截,Null的缓存时间也不应该太长,配合参数过滤,将部分请求过滤掉。
缓存击穿
问题
数据库中存在该数据,但缓存中不存在。当并发用户数特别大的时候,同时有多个请求到达应用服务器。就像缓存被凿开了一个洞——从一个点击穿了缓存。
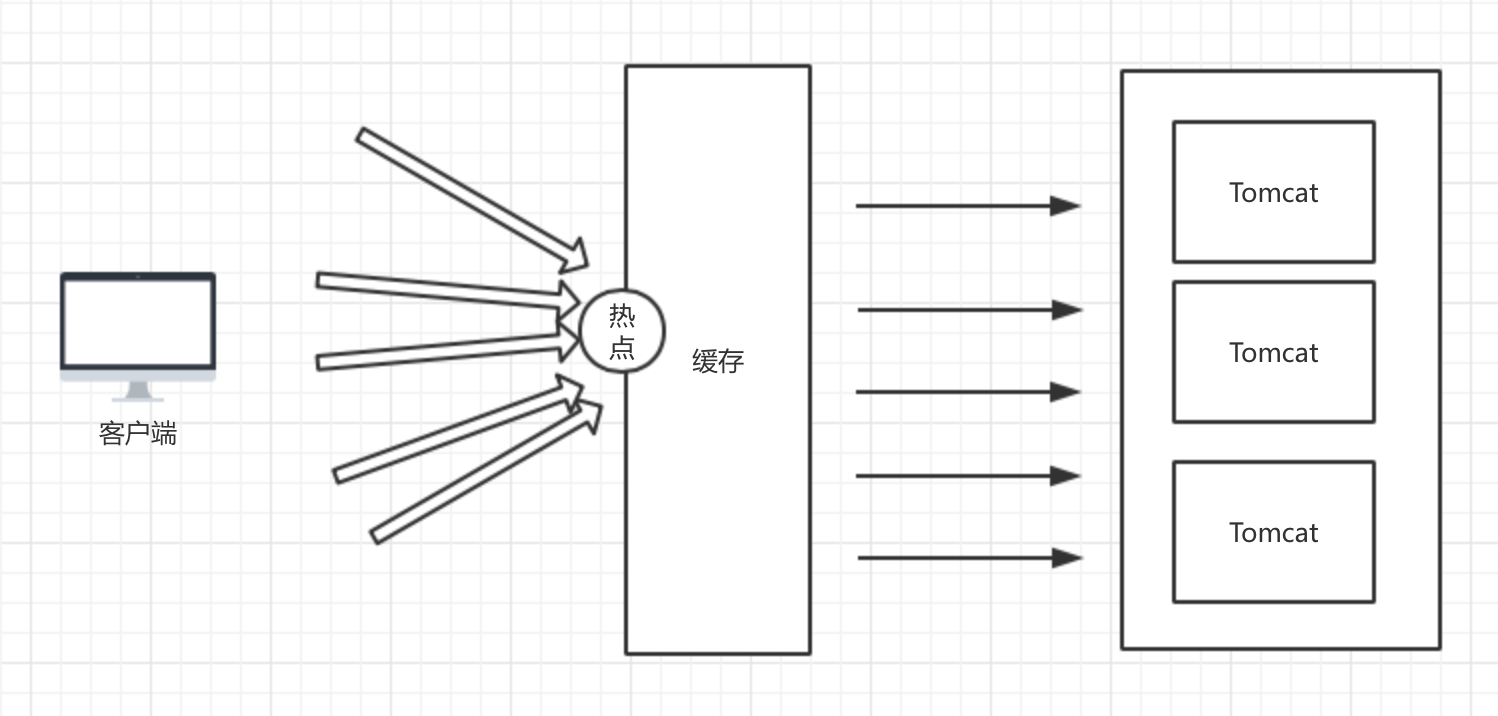
解决方案
首先,要意识到缓存击穿是客观存在的(热点数据的缓存过期、需求刚上线还没有进行缓存)。
当然,我们可以通过一些措施去尽量避免缓存击穿。
预热。上线某些功能的时候,刚开始是没有缓存的,上线前先通过脚本将热点数据提前缓存起来。
分布式锁。只有一个请求能去更新缓存,更新好之前其他请求先进行等待。
缓存雪崩
问题
大量热点数据过期,导致大量请求瞬间涌入后端服务器。超过了数据库的服务能力。
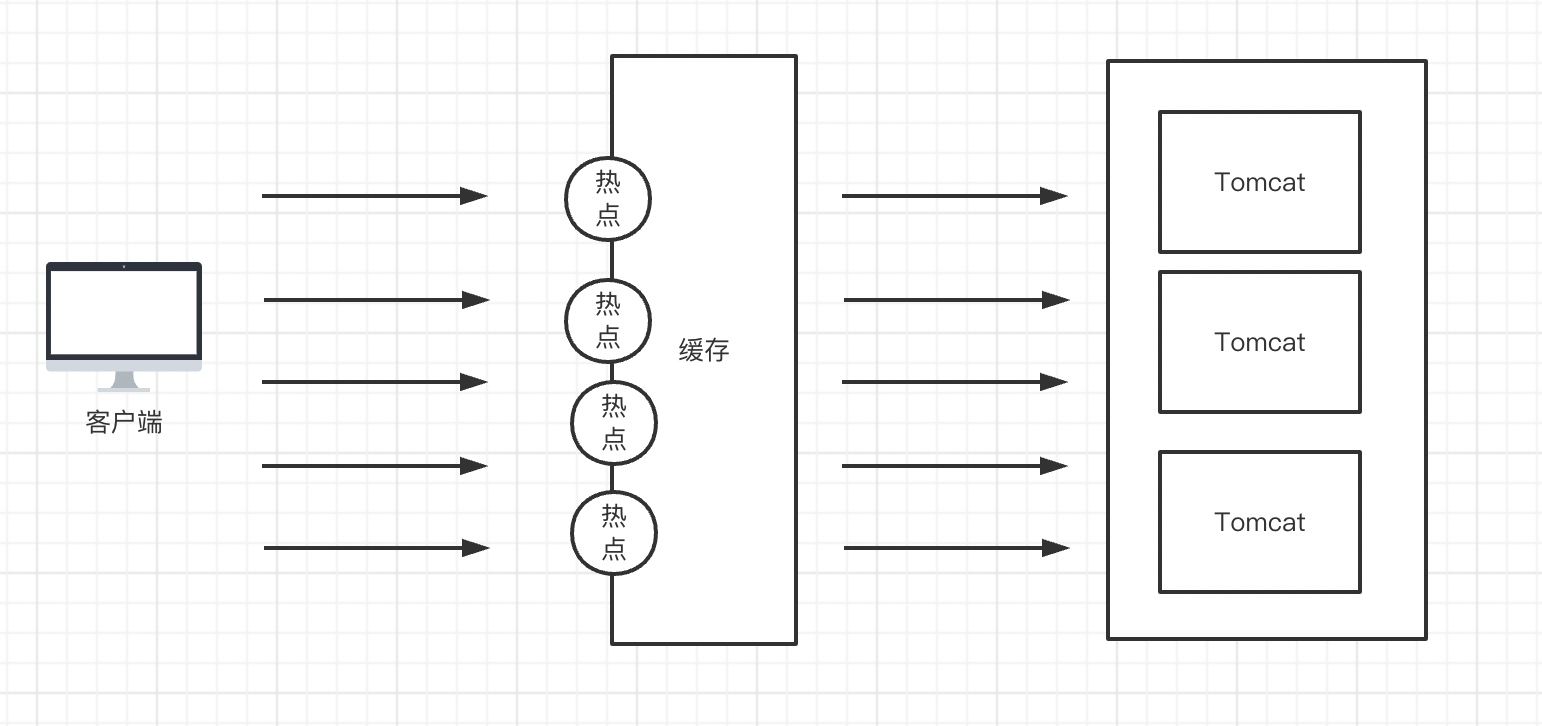
和缓存击穿不同的是,缓存击穿指的是某个热点数据的缓存不存在,而缓存雪崩指的是多个热点。
解决方案
既然缓存同时过期了,那么只要在设置缓存时间的时候添加一个随机数就好了。
String key = "test"; String value = "test"; long timeout = 1000 * 60; long random = new Random(2000).nextLong(); TimeUnit unit = TimeUnit.MILLISECONDS; redisTemplate.opsForValue().set(key , value ,timeout + random, unit);根据热点排序,热点数据缓存时间尽可能持久。
·
Redis常用操作
启动
启动服务
redis-server path(配置文件路径)
建立一个客户端连接
redis-cli -h 主机 -p 端口号 -a 密码
停止
redis-cli -h 主机 -p 端口号 -a 密码 shutdown
参考书目
《深入分布式缓存:从原理到实践》
《Redis实战》
《Redis深度历险:核心原理与应用实践》
《亿级流量网站架构核心技术》
一些网络Blog